Tensorflow Profilerを使って前処理 (tf.data.Dataset API) のパフォーマンスを改善する
Tensorflow Profilerの紹介を行い、tf.data.Dataset APIとtf.kerasで構成された画像分類タスクのパイプラインのパフォーマンス改善を試してみます。
目的は、以下です。
- Tensorflow Profilerの導入
- tf.data.Dataset APIの主要な高速化手法の効果を確認
Tensorflow Profiler
Tensorflow Profiler はTensorflowのコードをプロファイル (プログラムの処理時間や消費リソースを分析) するツールです。2020年5月頃にTensorflow Coreに仲間入り (リリース) しました。
Tensorflow Profilerは、全てのTensorflowオペレーションのパフォーマンスを捕捉します。tf.data.Dataset API で前処理を実装し、tf.kerasでモデルやmetricsを実装すると、学習時の全ての処理をプロファイリングし、ボトルネックを発見することでパフォーマンス改善に役立てることが可能です。
以下の様な項目が分析できます。
- Overview page: モデルのパフォーマンス概要と最適化項目提案
- Input pipeline analyzer: データ入力パイプラインの分析と最適化項目提案
- TensorFlow stats: Tensorflowオペレーションのパフォーマンス統計
- GPU kernel stats: GPUアクセラレーションカーネルのパフォーマンス統計
- Trace viewer: Tensorflowオペレーションの処理時間と実行環境 (CPU or GPU)の情報を時系列で表示
詳しくは、ドキュメント を参照して下さい。
Tensorflow Profilerは、TensorBoardのエクステンションとして使用でき、tf.kerasのtensorboard callbacksに統合されます。そして、学習時のプロファイリング結果をTensorBoard上で閲覧できます。
例えば、Trace Viewerは、次のように表示されます。各処理が一つのボックスになっており、大きさが処理時間の長さに対応しています。左から右に向かって時間が流れています。はじめにCPU上の処理 tf_Compute (前処理) が実行され、その後、GPU上の処理 Tensorflow Ops (モデルの学習) が走っていることが確認できます。(画像だと見づらいですが、実際は、動的にスケールできるので操作に慣れれば使いやすいと思います)
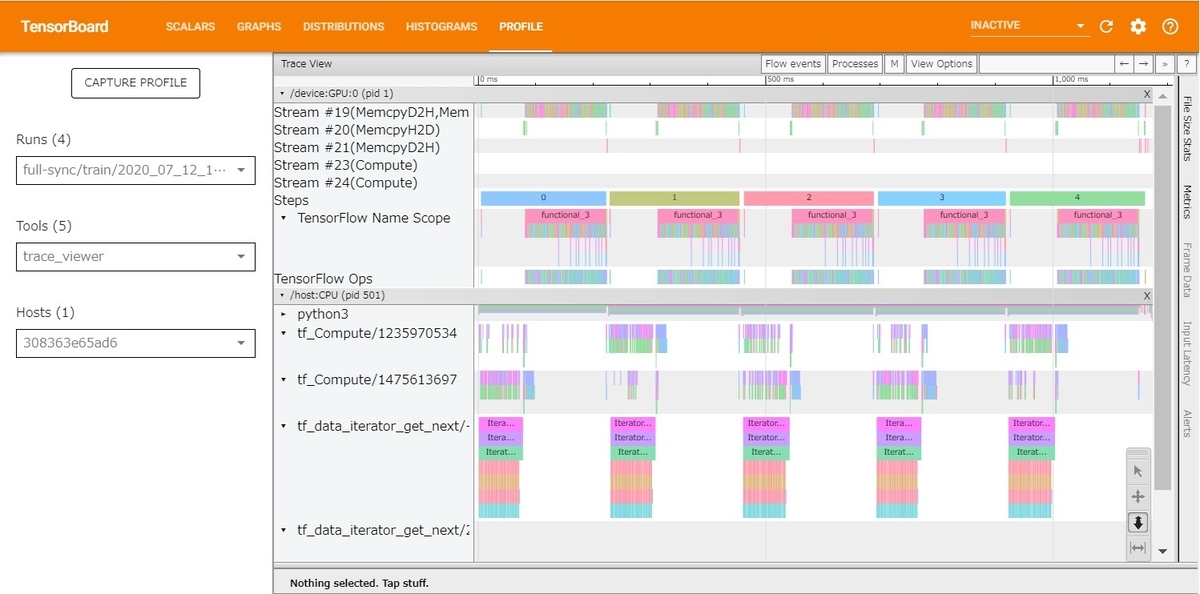
パイプライン
使用したコードはこちらです (Colab)。
構成
- 前処理: tf.data.Dataset APIを使用
- モデル: tf.keras.applications.EfficientNetB0をfine-tuning
- metrics: tf.keras.metrics.Accuracyを使用 (5クラス分類)
全てTensorflow APIを使用しています。
前処理
本記事では前処理に注目します。なので、前処理の流れを説明します。
データセットのファイル構造
データセットはjpegの画像ファイルです。以下の様に配置されています。
.
├── daisy
│ ├── a11.jpg
│ :
│ └── b11.jpg
├── dandelion
│ ├── a22.jpg
│ :
│ └── b22.jpg
├── roses
│ ├── a33.jpg
│ :
│ └── b33.jpg
├── sunflowers
│ ├── a44.jpg
│ :
│ └── b44.jpg
├── tulips
├── a55.jpg
:
└── b55.jpg
以上の構造を利用して、以下の様な、画像のパスとそのラベルをもつ pandas.DataFrame を作成します。(Tensorflow Profilerの範囲外なので割愛します。)
df.head() """ path label 0 /root/.keras/datasets/flower_photos/tulips/570... 4 1 /root/.keras/datasets/flower_photos/tulips/135... 4 2 /root/.keras/datasets/flower_photos/tulips/485... 4 3 /root/.keras/datasets/flower_photos/tulips/716... 4 4 /root/.keras/datasets/flower_photos/tulips/693... 4 """
前処理の実装(簡略化版)
tf.data.Dataset APIを使って以下の様な処理を行います。(高速化の余地を残すためにわざと下手な書き方をしています。)
import tensorflow as tf BUFFER_SIZE = 1223 # 総データ数 // 3 (総データ数に近づけるほど正しくシャッフルされる) BATCH_SIZE = 32 def load_and_preprocess_image(path: tf.Tensor) -> tf.Tensor: # ReadFile: 画像ファイル (jpeg) 読み込み image = tf.io.read_file(path) # jpeg画像をtensorに変換 image = tf.image.decode_jpeg(image, channels=3) # 画像サイズを固定サイズ (224, 224, 3) に変換 image = tf.image.resize(image, [224, 224]) return image path_ds = tf.data.Dataset.from_tensor_slices(df["path"].to_numpy()) # 前処理実行 path_ds = path_ds.map(load_and_preprocesss_image) label_ds = tf.data.Dataset.from_tensor_slices(df["label"].to_numpy()) # 画像とラベルの結合 ds = tf.data.Dataset.zip((path_ds, label_ds)) ds = ds.shuffle(buffer_size=BUFFER_SIZE) # 無限回繰り返しイテレーションできるように設定 ds = ds.repeat() # 1イテレーションでBATCH_SIZE個データを取り出せるように設定 ds = ds.batch(BATCH_SIZE)
Tensorflow Profilerの使用
セットアップ
今回、Google Colaboratoryを使用しました。Tensorflow Profilerがサポートされているので簡単に使えます。
以下を実行すると、起動できます。
!pip install -U tensorboard_plugin_profile # Load the TensorBoard notebook extension. %load_ext tensorboard # Launch TensorBoard and navigate to the Profile tab to view performance profile %tensorboard --logdir=logs
他の環境用のセットアップ手順はこちらのReadmeに記載されています。
使用
以下の様に指定すると、学習後にlogが吐き出されます。
from datetime import datetime logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S") tboard_callback = tf.keras.callbacks.TensorBoard( log_dir = logs, histogram_freq = 1, profile_batch = '110,120' # プロファイリングするイテレーション範囲を指定 ) history = model.fit(ds_train, batch_size=BATCH_SIZE, epochs=EPOCHS, steps_per_epoch=num_images//BATCH_SIZE, validation_data=ds_val, callbacks=(tboard_callback, ))
profile_batch はできるだけ小さくしたほうがいいです。TensorBoardが落ちやすくなってしまいます。
プロファイリング
シンプルな実装のプロファイリング結果
前述した前処理の実装でプロファイリングした結果が以下です。1 epochの最終5 イテレーション ~ 2 epoch目の最初 5 イテレーションあたりをプロファイリングしています。下図では対象の最初のイテレーション内の一連の処理が表示されています。上半分がGPUの処理 (modelの学習)、下半分がCPUの処理 (前処理)です。

1イテレーション分のデータの前処理が終わってからモデルの学習が始まっています。
CPUやGPUのリソースが消費されていない時間があるので改善の余地がありそうです。
Prefetch
tf.data.Dataset APIでは、GPU/TPUでの学習中にCPUで前処理を並列で走らせる機能が実装されています。リソースをより有効活用して、高速化が期待できます。
実装は、以下の様に前処理用の関数に一行追加するだけです。
...
ds = ds.batch(BATCH_SIZE)
# new!
ds = ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
先程と同様な範囲をプロファイリングした結果が以下です。GPUの処理とCPUの処理が同時に走っていることがわかります。余計な待ち時間を取り除くことができています。

これだけで、30 %程度高速化しています。Prefetchはどんな時でも (CPUしか使わない場合を除いて) 有効だと言われています。
また、CPU/GPUで同時に処理が走っていて、GPUでの処理の方が時間がかかっているので前処理の高速化はこれ以上意味がなさそうだということもわかります。
tf.data.Dataset API の高速化手法
これ以上の最適化は効果がなさそうだとわかりましたが、有名な高速化手法をまとめます。
ParallelMap
mapメソッドを並列計算して前処理の演算性能を上げます。
実装は、以下の様にmapの引数を追加するだけです。
path_ds = path_ds.map(load_and_preprocesss_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)
プロファイル結果は、以下です。tf_data_iterator_resourcesという項目に
Iterator::ParallelMapV2 という項目が追加されています。CPU自体の処理は速くなりますが、今回の条件では全体の高速化には寄与していません。

cache
tf.data.Dataset APIは前処理後のデータをキャッシュできます。メモリにキャッシュする場合とファイルにキャッシュする場合の2つあります。前者のほうが高速です。メモリが足りない場合に後者を使います。
実装は、以下の様になります。
... ds = tf.data.Dataset.zip((path_ds, label_ds)) # new! (メモリにキャッシュ) ds = ds.cache() # new! (ファイルにキャッシュ) ds = ds.cache(filename='./cache.tf-data') ...
今回は前処理がかるいのでほとんど恩恵を受けられないです。NLPで形態素解析が必要な場合などに真価を発揮すると思います。
終わりに
Tensorflow Profilerの紹介を行い、tf.data.Dataset APIとtf.kerasで構成された画像分類タスクのパイプラインのパフォーマンス改善を試してみました。
callbacksに追加するだけなので、簡単に導入することができました。
今回は注目していませんが、モデル内の各layerのプロファイリングも行っているので、モデル構造のボトルネックの発見にも役立ちそうです。
機械学習のパイプラインは並列処理やCPU/GPUなどの複数デバイスの使用が当たり前なので複雑な構造になり、ボトルネックの発見が容易ではないので、非常に重要なツールだと思います。